Biostatistics
Section outline
-
Note: if you want to gain a certificate for completing this course, you will have to be given an account by the administrator or create an account through the feedback form on the site home page and log in as a student.
Welcome to Biostatistics! This course comes from the Peoples-uni module prepared by Marija Noursis and is based on her e-book Basics of Biostatistics.
The course introduces you to the art and science of collecting, analyzing and interpreting data from medical and biological studies. Anyone who strives to improve human health based on empirical evidence must understand how to draw conclusions about populations based on data obtained from samples.
The module presents statistical concepts without invoking mathematical complexity. Instead, the emphasis is on intuitive, easy-to-grasp, explanations and lots of examples drawn from the medical literature. Open-source statistical software is used for analyzing data sets. Examples focus on issues that confront many low and middle-income countries. Basic maths and curiosity about the scientific method are the only prerequisites.
Upon completion of the module, you should be able to more confidently read the results sections of medical journals and to perform and interpret the results from frequently used statistical procedures.
Getting started
Course Structure and Expectations: The main reference for the course is the e-book Basics of Biostatistics, by Marija Norusis, which you can download by clicking here.
The course is structured into five topics. For each topic, we will direct you to the reading resources that have been prepared to help you meet the course competencies. The basis of learning is to read these resources, and reflect on them. In some cases, there are quizzes after the topic to allow you to self-assess your learning. It is expected that you read all core resources and contribute to all reflections in order to make the most of these learning opportunities.
For students who wish to explore more advanced topics, there is additional material that covers models for survival data, multiple regression and logistic regression.
The topics are:
1. Describing and Summarizing Data
2. Evaluating Results from Samples
3. Basics of Hypothesis Testing
4. Testing Hypotheses about Counts
5. Correlation and Regression
Statistical Software
Statistical software plays an important role in data analysis since almost all analyses are conducted using a computer. In this course we make limited use of some easy-to-use open-source software since we can't provide you with expensive proprietary software and time is too limited to teach R, which is a very powerful open-source software. If you have access to SPSS, SAS, Stata or another statistical software package, and know how to use it, then feel free to utilise it instead of the open-source applications suggested in the topic questions.
If you are interested in learning R, there are excellent free open online courses available.We hope that you will enjoy studying this module!

This work is licensed under a Creative Commons Attribution 4.0 International License. -
-
Topic 1
Learning outcomes: Recognize the importance of visual displays in conveying information. Select appropriate displays and summary statistics based on the type of data available.
Determine the scale on which variables are measured; interpret and construct frequently used graphical displays; calculate measures of central tendency and variability and determine their appropriateness for a given situation.
-
Students mustViewMake forum posts: 1
Reflect on this activity:
Female Genital Mutilation/Cutting (FGM/C) continues to be a public health concern in 29 countries. You have been charged with preparing a report on this problem, similar to the World Malaria Report described in Chapter 1 of the e-book. Describe 3 charts that you would include in your report.
Make sure to identify the type of chart and its elements clearly and structure your answers as follows.
1. Type of chart:
2. Which variable is represented on the x-axis? And what data type is it?
3. Which variable is represented on the y-axis? And what data type is it?
4. Do you have any other variables on the same chart, describe data the types for them too. -
Students mustViewReceive a grade
This quiz is based on the materials for Topic 1, Describing and Summarizing Data. We strongly encourage you to test yourself on how well you have understood the material. Once you submit the quiz, it will be automatically graded and you can see detailed explanations of the answers.
-
-
Topic 2
Learning outcomes: Understand the properties of random samples selected from a population. Appreciate the role of sample size and variability in the distribution of possible sample outcomes. Recognize the importance of the normal distribution in statistics.
Calculate and interpret a confidence interval for the population mean; explain the difference between the standard deviation of a set of observations and the standard error of the mean; use the standard normal distribution to test hypotheses about a population mean; define the observed significance level.
-
Students mustViewMake forum posts: 1
Please read “Chapter 2: Evaluating Results from Samples” in the course text (Basics of Biostatistics)
Activity:
We are asking each of you to manufacture twenty hypothetical patients and to "treat" them, assuming a cure rate of 50%.
Firstly, determine whether each of the patients is "cured" using a procedure in which the probability of a "cure" is 50%. Each patient should an equal chance of being cured or not cured.
Count how many "cures" you have for the first 5 patients, the first 10 patients and then all 20 patients.
Use GraphPad to calculate the confidence interval for each of the three groups of patients (first 5 patients, first 10 patients and all 20 patients). (www.graphpad.com/quickcalcs/confinterval2 ).
Reflect on:
1. How you randomly determined whether each of the hypothetical patients is cured or not
2. The 90%, the 95% and the 99% confidence interval for the true cure rate for each of the three groups
3. Interpret the confidence intervals and explain why they are of different lengths
4. Can you reject the null hypothesis that the true population cure rate is 50% based on any of your samples?
-
-
Topic 3
Learning outcomes: Understand the basic steps of using statistical methods to test a hypothesis about populations based on results observed in random samples from the populations.
Be able to formulate a null hypothesis and an alternative hypothesis; understand the rationale for rejecting a null hypothesis; explain the errors that you can make when testing a hypothesis; describe the importance of sample size for testing hypotheses. Be able to test simple hypotheses about population means using the paired and independent samples t-test and analysis of variance and be able to correctly interpret the results of hypothesis testing.
-
Students mustViewMake forum posts: 1
Reading:
Chapter 4 (all) and Chapter 5 (up to page 115 only) in the e-book.
ActivityThese are questions to check your understanding of the topic.
Answer any five of these questions.
Q1: A school principal wants to test if it is true what teachers say – that high school juniors use the computer an average 3.2 hours a day. What are our null and alternative hypotheses?
Q2: Duracell manufactures batteries that the CEO claims will last an average of 300 hours under normal use. A researcher randomly selected 20 batteries from the production line and tested these batteries. The tested batteries had a mean life span of 270 hours with a standard deviation of 50 hours. Do we have enough evidence to suggest that the claim of an average lifetime of 300 hours is false? (HINT: A. state the null and alternative hypotheses; B. choose an appropriate statistical test; C. state the level of statistical significance and the conclusion)
Q3: If the difference between the hypothesized population mean and the mean of the sample is large, we ___ the null hypothesis. If the difference between the hypothesized population mean and the mean of the sample is small, we ___ the null hypothesis
Q4: At the Chrysler manufacturing plant, there is a part that is supposed to weigh precisely 19 pounds. The engineers take a sample of parts and want to know if they meet the weight specifications. What are our null and alternative hypotheses?
Q5: A group of students have an average SAT score of 1,020. From a random sample of 144 students we find the average SAT score to be 1,100 with a standard deviation of 144. We want to know if these high school students are representative of the overall population. What are our null and alternative hypotheses?
Q6: A farmer is trying out a planting technique that he hopes will increase the yield on his pea plants. The average number of pods on one of his pea plants is 145 pods with a standard deviation of 100 pods. This year, after trying his new planting technique, he takes a random sample of his plants and finds the average number of pods to be 147. He wonders whether or not this is a statistically significant increase. What are his hypotheses and the test statistic? (HINT: A. First, we develop our null and alternative hypotheses; B. Next, we calculate the test statistic (use z-score) for the sample of pea plants.)
-
-
Topic 4
Learning outcomes: Understand the statistical meaning of independence of the rows and columns of a table. Appreciate the importance of quantifying the association between a risk factor and an outcome.
Calculate a chi-square test of independence; identify the necessary assumptions; discuss the effect of sample size on your conclusions. Calculate and interpret a relative risk ratio and an odds ratio. Explain their importance.
-
Students mustViewMake forum posts: 1Welcome to Topic 4! You are more than half way through the module, so don't forget to give yourselves a congratulatory pat on the back!
Before you attempt the exercise, please read the remainder of Chapter 5 in the e-book.
In topic 3, we learned how to test hypotheses about population means. In this topic, we will look at count data. Read on for the exercise questions…
Exercise: Results for travel to a high-burden TB country.
In this study, 300 children received a tuberculin skin test (TST), of which 80 had a positive TST result. [Note: parents of all included children consented to be in this study.]
Of the 300 children, we know 22 had travelled to a high-burden TB country during the 12 months prior to their TST.
We also know 12 of the 80 children with a positive TST had travelled to a high-burden TB country during the 12 months before their skin test.
Q1: Populate this table using the information provided above
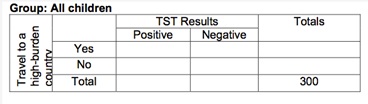
Once you have done this:
Q2: Formulate a hypothesis for this question
Q3: Choose an appropriate test statistic to test the association and justify the use of the statistic
Q4: Calculate an odds ratio (OR) and provide an interpretation of the findings.
Q5: Calculate a relative risk ratio (RR) and provide an interpretation of the findings.
You can use any statistical package available to you if needed!
-
Students mustViewReceive a gradeReceive a passing grade
Practice questions for Topic 4.
-
-
Topic 5
Learning outcomes: Appreciate the importance of quantifying the strength of the linear relationship between two variables. Understand how a linear regression model can be used to predict the values of a dependent variable from one or more independent variables.
Know when it is appropriate to calculate a correlation coefficient and how to interpret it. Understand the role of the slope, intercept, residual, and predicted value in a linear regression model. Know how to determine how well a regression model fits the observed data.
-
Students mustViewMake forum posts: 1
The reading for this discussion topic is pp. 133-168 in the e-book.
Question:
Much research focuses on the relationships between variables, often with one of the variables considered a dependent variable and the others independent (predictor) variable.
- Give an example in your field of a dependent variable and a set of predictor variables that may be related to the dependent variable. For example, you may want to know if ITN use is related to age, gender, education and marital status.
- Do you think your predictor variables are related to each other? If so, briefly describe how you think the variables are related.
- Do you think the relationship between pairs of predictors is linear?
- What disadvantages do you see to examining the relationship of each of the predictor variables with the dependent variable, ignoring the other predictor variables?
-
-
We are not able to offer a certificate stating that you have gained knowledge without having viewed your reflection posts or a more extensive assessment. However we are able to offer a certificate that you have completed the course is you have accessed the resources, posted to the reflection forums and passed the quizzes.